⚠ INFO ⚠
This document discusses non-API components of Ax, which may be subject to backwards compatibility breaking changes between major library versions.
Utilizing and Creating Ax Analyses
Ax’s Analysis module provides a framework for producing plots, tables, messages, and
more to help users understand their experiments. This is facilitated via the Analysis
protocol and its various subclasses.
Analysis classes implement a method compute which consumes an Experiment,
GenerationStrategy, and/or Adapter and outputs an AnalysisCardBase. This can
either be an AnalysisCard, which contains a dataframe with relevant data, a “blob”
which contains data to be rendered (ex. a plot), and miscellaneous metadata like a title
and subtitle. It could also be an AnalysisCardGroup which contains a name and list of
children AnalyisCardBase -- this allows cards to exist within nested groups as is
relevant. For example: the TopSurfacesPlot computes a SensitivityAnalysisPlot to
understand which parameters in the search space are most relevent, then produces
SlicePlots and ContourPlots for the most important surfaces.
Importantly Ax is able to save these cards to the database using save_analysis_cards,
allowing for analyses to be pre-computed and displayed at a later time. This is done
automatically when Client.compute_analyses is called.
Using Analyses
The simplest way to use an Analysis is to call Client.compute_analyses. This will
heuristically select the most relevant analyses to compute, save the cards to the
database, return them, and display them in your IPython environment if possible. Users
can also specify which analyses to compute and pass them in manually, for example:
client.compute_analyses(analyses=[TopSurfacesPlot(), Summary(), ...]).
When developing a new Analysis it can be useful to compute an analysis "a-la carte".
To do this, manually instantiate the Analysis and call its compute method. This will
return a collection of AnalysisCards which can be displayed.
from ax.api.client import Client
from ax.api.configs import RangeParameterConfig
# Create a Client and populate it with some data
client = Client()
client.configure_experiment(
name="booth_function",
parameters=[
RangeParameterConfig(
name="x1",
bounds=(-10.0, 10.0),
parameter_type="float",
),
RangeParameterConfig(
name="x2",
bounds=(-10.0, 10.0),
parameter_type="float",
),
],
)
client.configure_optimization(objective="-1 * booth")
for _ in range(10):
for trial_index, parameters in client.get_next_trials(max_trials=1).items():
client.complete_trial(
trial_index=trial_index,
raw_data={
"booth": (parameters["x1"] + 2 * parameters["x2"] - 7) ** 2
+ (2 * parameters["x1"] + parameters["x2"] - 5) ** 2
},
)
[INFO 06-09 17:11:02] ax.storage.sqa_store.with_db_settings_base: Ax SQL storage initialized with SQLAlchemy 1.4.17
[INFO 06-09 17:11:02] ax.api.client: GenerationStrategy(name='Center+Sobol+MBM:fast', nodes=[CenterGenerationNode(next_node_name='Sobol', use_existing_trials_for_initialization=True), GenerationNode(name='Sobol', generator_specs=[GeneratorSpec(generator_enum=Sobol, generator_key_override=None)], transition_criteria=[MinTrials(transition_to='MBM'), MinTrials(transition_to='MBM')], suggested_experiment_status=ExperimentStatus.INITIALIZATION, pausing_criteria=[MaxTrialsAwaitingData(threshold=5)]), GenerationNode(name='MBM', generator_specs=[GeneratorSpec(generator_enum=BoTorch, generator_key_override=None)], transition_criteria=None, suggested_experiment_status=ExperimentStatus.OPTIMIZATION, pausing_criteria=None)]) chosen based on user input and problem structure.
[INFO 06-09 17:11:02] ax.api.client: Generated new trial 0 with parameters {'x1': 0.0, 'x2': 0.0} using GenerationNode CenterOfSearchSpace.
[INFO 06-09 17:11:02] ax.api.client: Trial 0 marked COMPLETED.
[INFO 06-09 17:11:02] ax.api.client: Generated new trial 1 with parameters {'x1': 6.593081, 'x2': -8.203056} using GenerationNode Sobol.
[INFO 06-09 17:11:02] ax.api.client: Trial 1 marked COMPLETED.
[INFO 06-09 17:11:02] ax.api.client: Generated new trial 2 with parameters {'x1': -0.23816, 'x2': 5.738095} using GenerationNode Sobol.
[INFO 06-09 17:11:02] ax.api.client: Trial 2 marked COMPLETED.
[INFO 06-09 17:11:02] ax.api.client: Generated new trial 3 with parameters {'x1': -6.528561, 'x2': -4.96046} using GenerationNode Sobol.
[INFO 06-09 17:11:02] ax.api.client: Trial 3 marked COMPLETED.
[INFO 06-09 17:11:02] ax.api.client: Generated new trial 4 with parameters {'x1': 0.388369, 'x2': 2.41798} using GenerationNode Sobol.
[INFO 06-09 17:11:02] ax.api.client: Trial 4 marked COMPLETED.
[INFO 06-09 17:11:03] ax.api.client: Generated new trial 5 with parameters {'x1': 2.193741, 'x2': 10.0} using GenerationNode MBM.
[INFO 06-09 17:11:03] ax.api.client: Trial 5 marked COMPLETED.
[INFO 06-09 17:11:03] ax.api.client: Generated new trial 6 with parameters {'x1': -1.39824, 'x2': 4.190411} using GenerationNode MBM.
[INFO 06-09 17:11:03] ax.api.client: Trial 6 marked COMPLETED.
[INFO 06-09 17:11:03] ax.api.client: Generated new trial 7 with parameters {'x1': -5.238646, 'x2': 10.0} using GenerationNode MBM.
[INFO 06-09 17:11:03] ax.api.client: Trial 7 marked COMPLETED.
[INFO 06-09 17:11:04] ax.api.client: Generated new trial 8 with parameters {'x1': 4.589433, 'x2': 0.39767} using GenerationNode MBM.
[INFO 06-09 17:11:04] ax.api.client: Trial 8 marked COMPLETED.
[INFO 06-09 17:11:04] ax.api.client: Generated new trial 9 with parameters {'x1': 1.814576, 'x2': 2.493672} using GenerationNode MBM.
[INFO 06-09 17:11:04] ax.api.client: Trial 9 marked COMPLETED.
from ax.analysis.plotly.parallel_coordinates import ParallelCoordinatesPlot
analysis = ParallelCoordinatesPlot()
analysis.compute(
experiment=client._experiment,
generation_strategy=client._generation_strategy,
# compute can optionally take in an Adapter directly instead of a GenerationStrategy
adapter=None,
)
Parallel Coordinates for booth
The parallel coordinates plot displays multi-dimensional data by representing each parameter as a parallel axis. This plot helps in assessing how thoroughly the search space has been explored and in identifying patterns or clusterings associated with high-performing (good) or low-performing (bad) arms. By tracing lines across the axes, one can observe correlations and interactions between parameters, gaining insights into the relationships that contribute to the success or failure of different configurations within the experiment.
Creating a new Analysis
Let's implement a simple Analysis that returns a table counting the number of trials in
each TrialStatus . We'll make a new class that implements the Analysis protocol
(i.e. it defines a compute method).
import random
from typing import Sequence
import pandas as pd
from ax.analysis.analysis import (
Analysis,
AnalysisCard,
)
from ax.core.experiment import Experiment
from ax.generation_strategy.generation_strategy import GenerationStrategy
from ax.adapter.base import Adapter
class TrialStatusTable(Analysis):
def compute(
self,
experiment: Experiment | None = None,
generation_strategy: GenerationStrategy | None = None,
adapter: Adapter | None = None,
) -> AnalysisCard:
trials_by_status = experiment.trials_by_status
records = [
{"status": status.name, "count": len(trials)}
for status, trials in trials_by_status.items()
if len(trials) > 0
]
return self._create_analysis_card(
title="Trials by Status",
subtitle="How many trials are in each status?",
df=pd.DataFrame.from_records(records),
)
# Let's add some more trials of miscellaneous statuses before computing the new Analysis
for _ in range(10):
for trial_index, parameters in client.get_next_trials(max_trials=1).items():
roll = random.random()
if roll < 0.2:
client.mark_trial_failed(trial_index=trial_index)
elif roll < 0.5:
client.mark_trial_abandoned(trial_index=trial_index)
else:
client.complete_trial(
trial_index=trial_index,
raw_data={
"booth": (parameters["x1"] + 2 * parameters["x2"] - 7) ** 2
+ (2 * parameters["x1"] + parameters["x2"] - 5) ** 2
},
)
# Client.compute_analyses will display cards individually if display=True
card = client.compute_analyses(analyses=[TrialStatusTable()], display=True)
[INFO 06-09 17:11:06] ax.api.client: Generated new trial 10 with parameters {'x1': -10.0, 'x2': 8.142475} using GenerationNode MBM.
[INFO 06-09 17:11:06] ax.api.client: Trial 10 marked COMPLETED.
[INFO 06-09 17:11:06] ax.api.client: Generated new trial 11 with parameters {'x1': 10.0, 'x2': -0.421998} using GenerationNode MBM.
[INFO 06-09 17:11:06] ax.api.client: Trial 11 marked COMPLETED.
[INFO 06-09 17:11:07] ax.api.client: Generated new trial 12 with parameters {'x1': 2.383825, 'x2': 1.11708} using GenerationNode MBM.
[INFO 06-09 17:11:07] ax.api.client: Trial 12 marked COMPLETED.
[INFO 06-09 17:11:07] ax.api.client: Generated new trial 13 with parameters {'x1': 0.668349, 'x2': 3.129648} using GenerationNode MBM.
[INFO 06-09 17:11:07] ax.api.client: Trial 13 marked FAILED.
[INFO 06-09 17:11:08] ax.api.client: Generated new trial 14 with parameters {'x1': 0.547364, 'x2': 3.225755} using GenerationNode MBM.
[INFO 06-09 17:11:08] ax.api.client: Trial 14 marked COMPLETED.
[INFO 06-09 17:11:08] ax.api.client: Generated new trial 15 with parameters {'x1': -1.938174, 'x2': 5.640184} using GenerationNode MBM.
[INFO 06-09 17:11:08] ax.api.client: Trial 15 marked FAILED.
[INFO 06-09 17:11:08] ax.api.client: Generated new trial 16 with parameters {'x1': -1.962088, 'x2': 5.664384} using GenerationNode MBM.
[INFO 06-09 17:11:08] ax.api.client: Trial 16 marked COMPLETED.
[INFO 06-09 17:11:09] ax.api.client: Generated new trial 17 with parameters {'x1': 1.510094, 'x2': 2.293941} using GenerationNode MBM.
[INFO 06-09 17:11:09] ax.api.client: Trial 17 marked FAILED.
[INFO 06-09 17:11:09] ax.api.client: Generated new trial 18 with parameters {'x1': 1.452779, 'x2': 2.352051} using GenerationNode MBM.
[INFO 06-09 17:11:09] ax.api.client: Trial 18 marked FAILED.
[INFO 06-09 17:11:09] ax.api.client: Generated new trial 19 with parameters {'x1': 1.456043, 'x2': 2.33109} using GenerationNode MBM.
[INFO 06-09 17:11:09] ax.api.client: Trial 19 marked FAILED.
Trials by Status
How many trials are in each status?
| status | count | |
|---|---|---|
| 0 | FAILED | 5 |
| 1 | COMPLETED | 15 |
Adding options to an Analysis
Imagine we wanted to add an option to change how this analysis is computed, say we wish
to toggle whether the analysis computes the number of trials in a given state or the
percentage of trials in a given state. We cannot change the input arguments to
compute, so this must be added elsewhere.
The analysis' initializer is a natural place to put additional settings. We'll create a
TrialStatusTable.__init__ method which takes in the option as a boolean, then modify
compute to consume this option as well. Following this patterns allows users to
specify all relevant settings before calling Client.compute_analyses while still
allowing the underlying compute call to remain unchanged. Standarization of the
compute call simplifies logic elsewhere in the stack.
class TrialStatusTable(Analysis):
def __init__(self, as_fraction: bool) -> None:
super().__init__()
self.as_fraction = as_fraction
def compute(
self,
experiment: Experiment | None = None,
generation_strategy: GenerationStrategy | None = None,
adapter: Adapter | None = None,
) -> AnalysisCard:
trials_by_status = experiment.trials_by_status
denominator = len(experiment.trials) if self.as_fraction else 1
records = [
{"status": status.name, "count": len(trials) / denominator}
for status, trials in trials_by_status.items()
if len(trials) > 0
]
# Use _create_analysis_card rather than AnalysisCard to automatically populate relevant metadata
return self._create_analysis_card(
title="Trials by Status",
subtitle="How many trials are in each status?",
df=pd.DataFrame.from_records(records),
)
card = client.compute_analyses(
analyses=[TrialStatusTable(as_fraction=True)], display=True
)
Trials by Status
How many trials are in each status?
| status | count | |
|---|---|---|
| 0 | FAILED | 0.25 |
| 1 | COMPLETED | 0.75 |
Plotly Analyses
Analyses do not just have to be Pandas dataframes. Ax also defines a class
PlotlyAnalysisCard containing both a dataframe and a plotly Figure.
Let's create a bar chart based on TrialStatusTable.
from ax.analysis.plotly.plotly_analysis import PlotlyAnalysisCard, create_plotly_analysis_card
from plotly import express as px
class TrialStatusTable(Analysis):
def __init__(self, as_fraction: bool) -> None:
super().__init__()
self.as_fraction = as_fraction
def compute(
self,
experiment: Experiment | None = None,
generation_strategy: GenerationStrategy | None = None,
adapter: Adapter | None = None,
) -> PlotlyAnalysisCard:
trials_by_status = experiment.trials_by_status
denominator = len(experiment.trials) if self.as_fraction else 1
records = [
{"status": status.name, "count": len(trials) / denominator}
for status, trials in trials_by_status.items()
if len(trials) > 0
]
df = pd.DataFrame.from_records(records)
# Create a Plotly figure using the df we generated before
fig = px.bar(df, x="status", y="count")
# Use _create_plotly_analysis_card rather than AnalysisCard to automatically populate relevant metadata
return create_plotly_analysis_card(
name=self.__class__.__name__,
title="Trials by Status",
subtitle="How many trials are in each status?",
df=df,
fig=fig,
)
card = client.compute_analyses(
analyses=[TrialStatusTable(as_fraction=True)], display=True
)
Trials by Status
How many trials are in each status?
Example Analyses in Ax
Ax offers a wide range of analyses to help you monitor optimization results, gain deeper insights into parameters and metrics based on model learning, and assess model diagnostics to ensure your optimization is progressing effectively.
The following table contains examples of each Analysis currently implemented in Ax:
| Name | Description | Example |
|---|---|---|
| Metric Effects | Shows predicted metric changes per arm using Ax's model, adjusted for noise and data non-stationarity for more reliable long-term effects. Can also plot raw “Observed” effects for the arms instead of model predicted effects. | 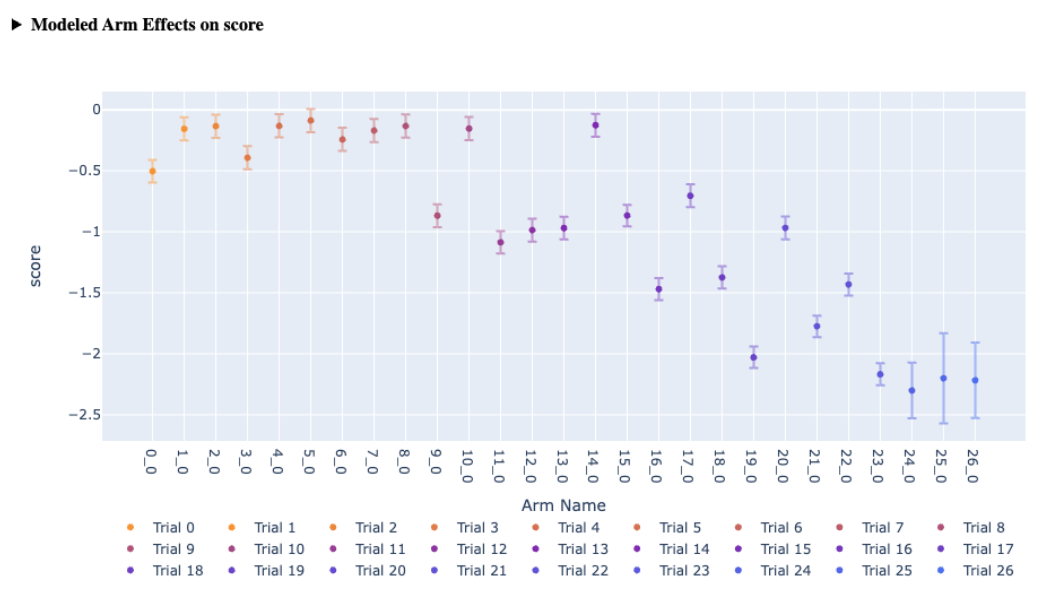 |
| Scatter Plot | Displays effects of each arm on two metrics, useful for visualizing trade-offs and the Pareto frontier. | 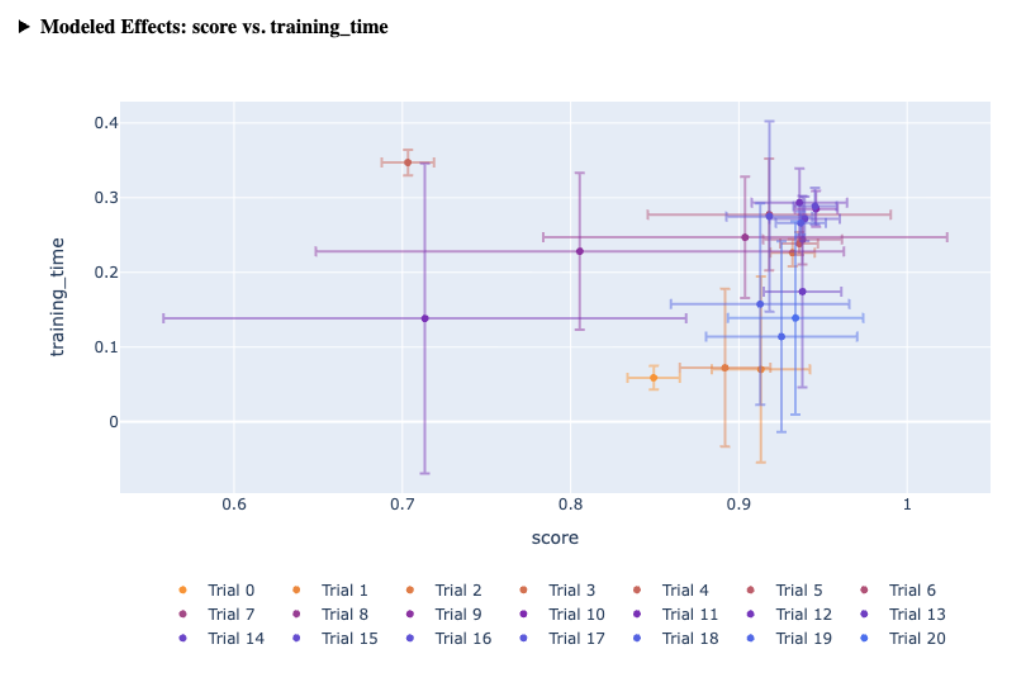 |
| Slice Plot | One-dimensional view of predicted outcomes for a given metric by varying one parameter, with others fixed at a baseline. | 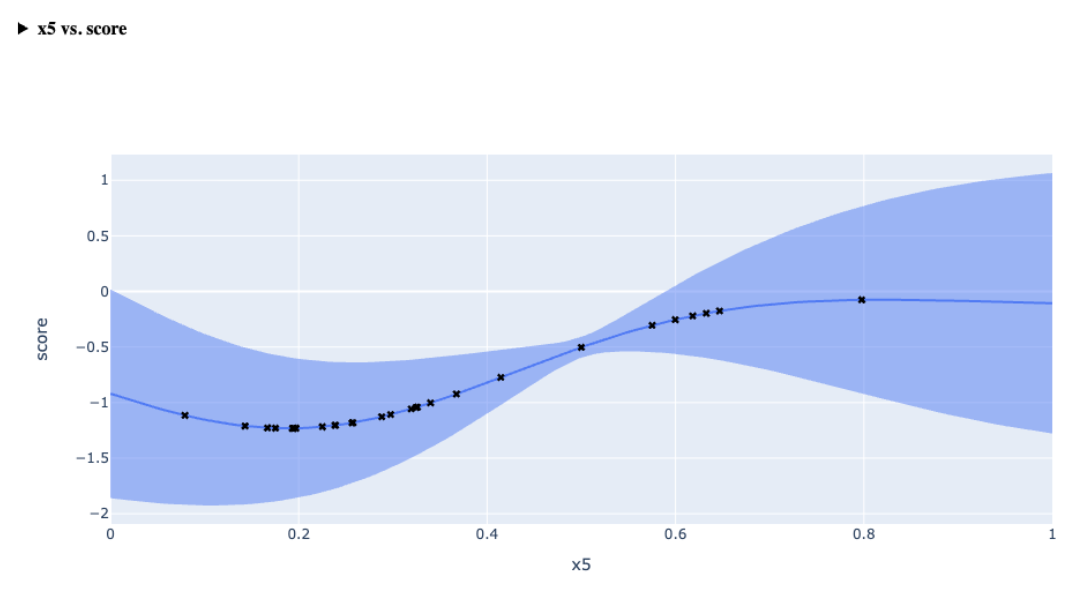 |
| Sensitivity Analysis | Shows how each parameter influences a metric via second-order sensitivity analysis. Helps identify which parameters have the greatest impact on a specific metric and whether their influence is positive or negative. | 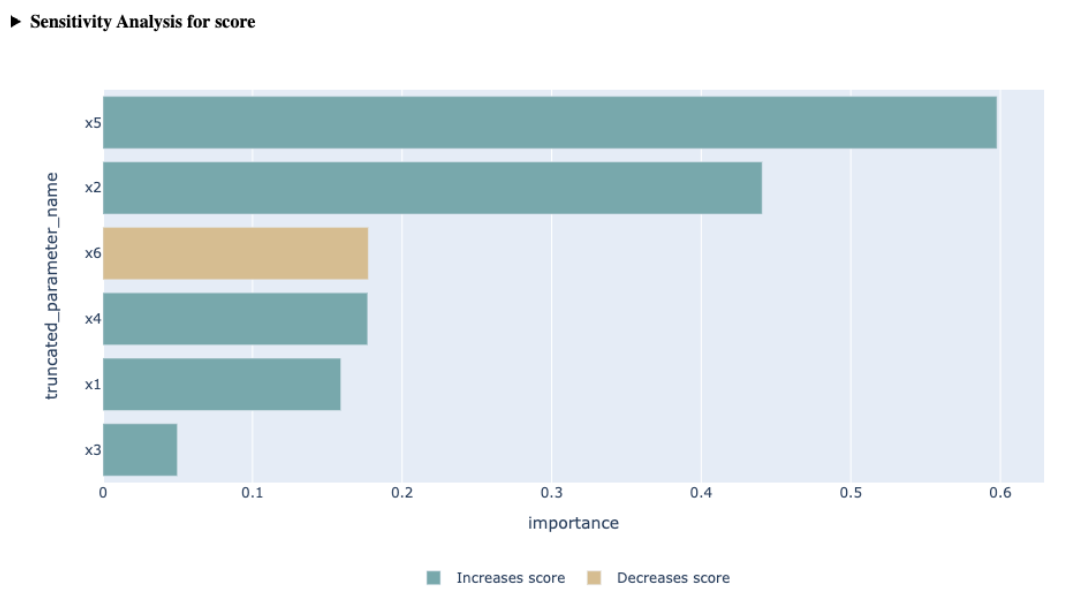 |
| Contour Plot | Visualizes predicted metric outcomes over two parameters, highlighting optimal regions and gradients. | 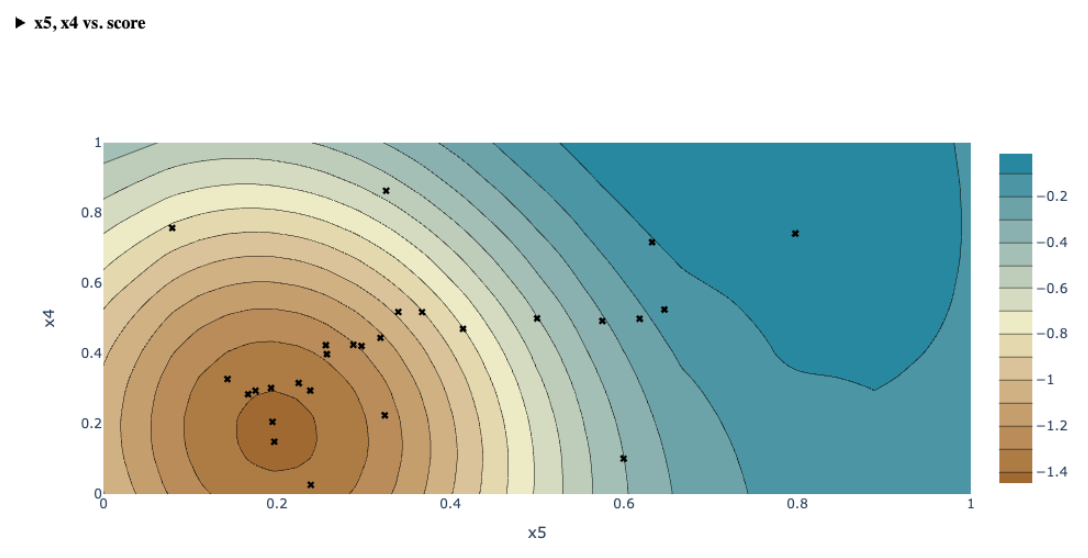 |
| Cross Validation Plot | Compares model predictions to actual values using leave-one-out validation, showing fit quality and prediction uncertainty. | 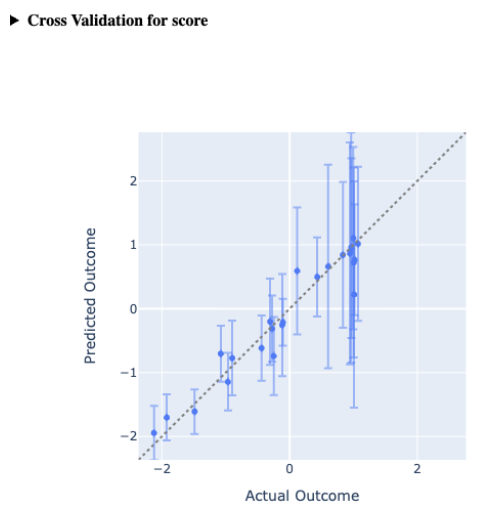 |
| Parallel Coordinates Plot | Represents multi-dimensional parameters on parallel axes to assess search space coverage and identify patterns in performance. | 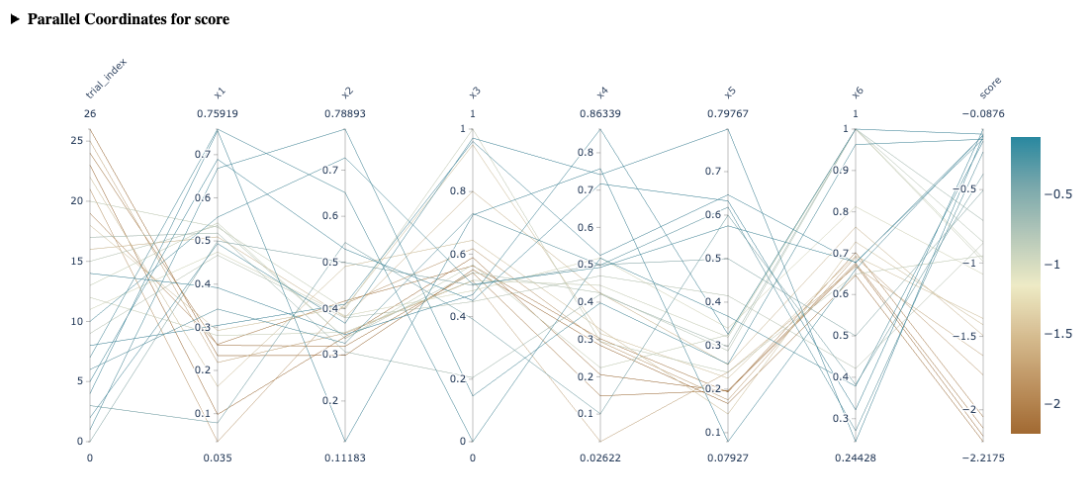 |
| Summary | Provides a high level summary of all arms/trials + metric results of your experiment in a tabular manner. | 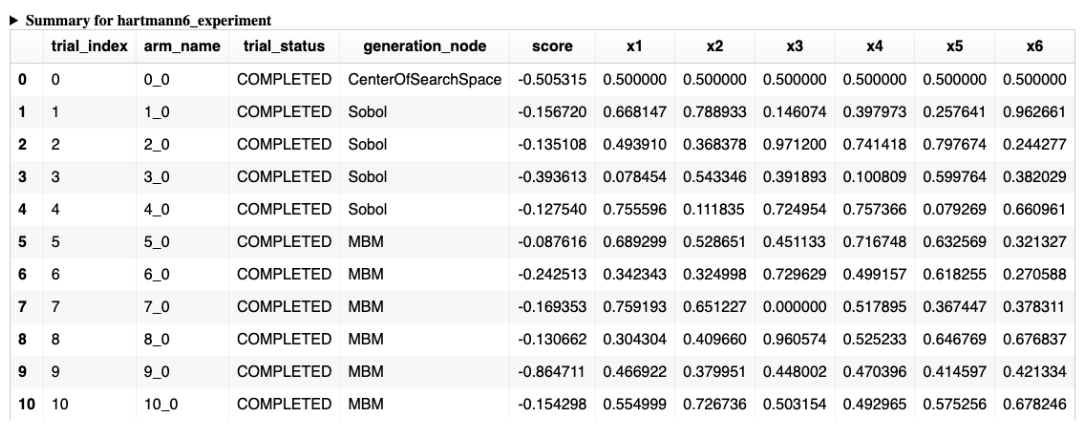 |
| Metric Summary | Tabular view of the metrics in the experiment. |  |
| Search Space Summary | Tabular view of the search space on the experiment. | 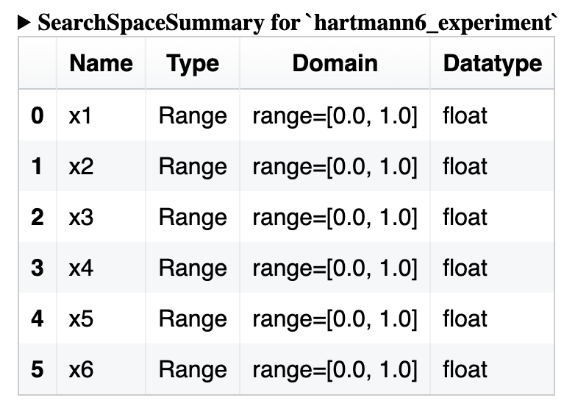 |
Miscellaneous tips
- Many analyses rely on the same infrastructure and utility functions -- check to see if
what you need has already been implemented somewhere.
- Many analyses require an
Adapterbut can use either theAdapterprovided or the currentAdapteron theGenerationStrategy--extract_relevant_adapterhandles this in a consistent way - Analyses which use an
Armas the fundamental unit of analysis will find theprepare_arm_datautility useful; using it will also lend theAnalysisuseful features like relativization for free
- Many analyses require an
- When writing a new
PlotlyAnalysischeck outax.analysis.plotly.utilsfor guidance on using color schemes and unified tool tips - Try to follow consistent design patterns; many analyses take an optional list of
metric_nameson initialization, and interpretNoneto mean the user wants to compute a card for each metric present. Following these conventions makes things easier for downstream consumers.