This document discusses non-API components of Ax, which may change between major library versions. Contributor guides are most useful for developers intending to publish PRs to Ax, not those using Ax directly or building tools on top of Ax.
Orchestration
Orchestrating adaptive experiments can get arbitrarily complex, depending on the nature of the trials and how they are evaluated. Key considerations typically include:
- Capacity management,
- Smart failure tolerance,
- Experiment state storage,
- Applying early-stopping,
- Building diagnostics into the process and generating insights during experiment,
- Logging what’s going on in the optimization.
Ax can orchestrate complete experiments using the built-in Orchestrator that
interfaces with an external system (e.g. training job queue, a physics simulator
or an A/B test management system), through simple, modular integration
components provided by the user (Runner and Metric).
Before proceeding, we recommend ensuring familiarity with Internal Organization of Ax: Experiment + Trials.
Ax Orchestrator component
Orchestrator is a "closed-loop" manager class in Ax that continuously deploys
trial runs to an arbitrary external system asynchronously, polls their status
from that system, fetches data when ready, and leverages known trial results to
generate more trials. The Orchestrator abstracts away the common but complex
orchestration and scheduling logic, behind a configurable interface.
In a nutshell, it loops through steps 1-5, adapting to the state of the trial evaluation system:
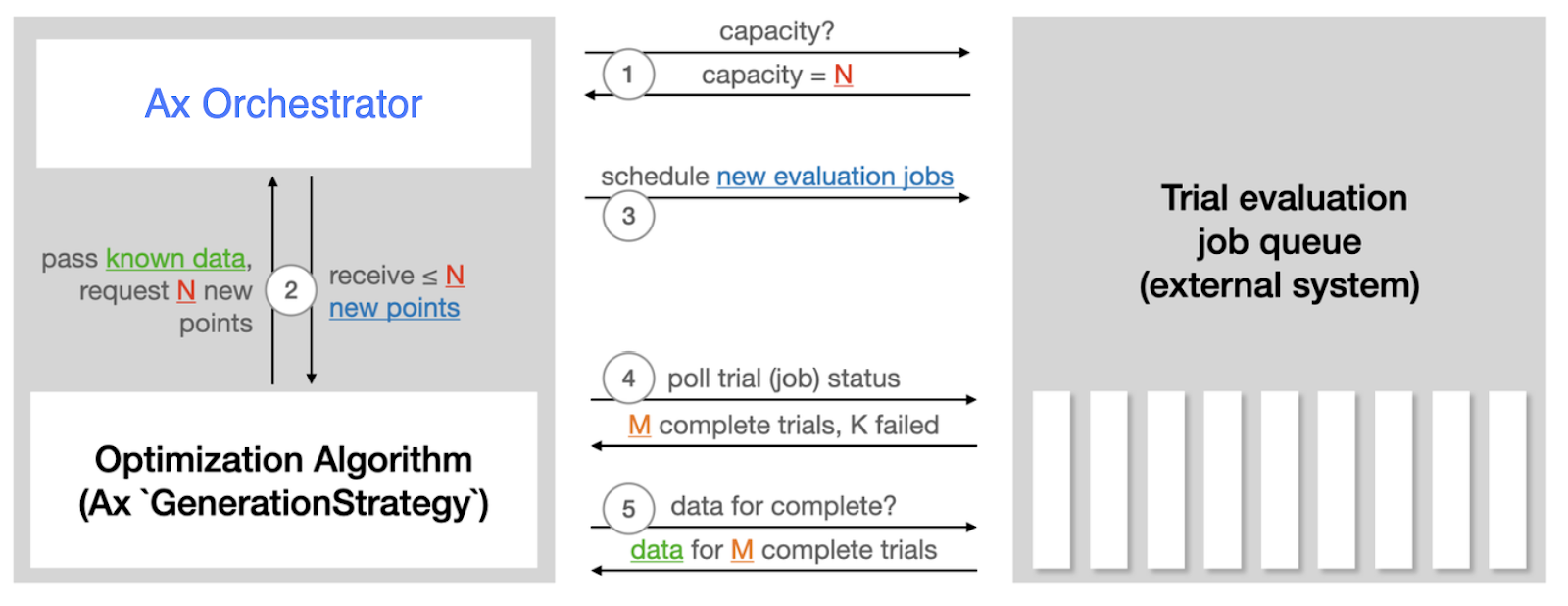
Key features of the Orchestrator include:
- Conduct the entire experiment in a "closed loop" fashion (in one line of code),
- Maintain user-set concurrency limits for trials run in parallel,
- Keep track of tolerated level of failed trial runs and otherwise 'manage' the optimization,
- Support SQL storage and allows for easy resumption of stored experiments.
Metrics and Runners
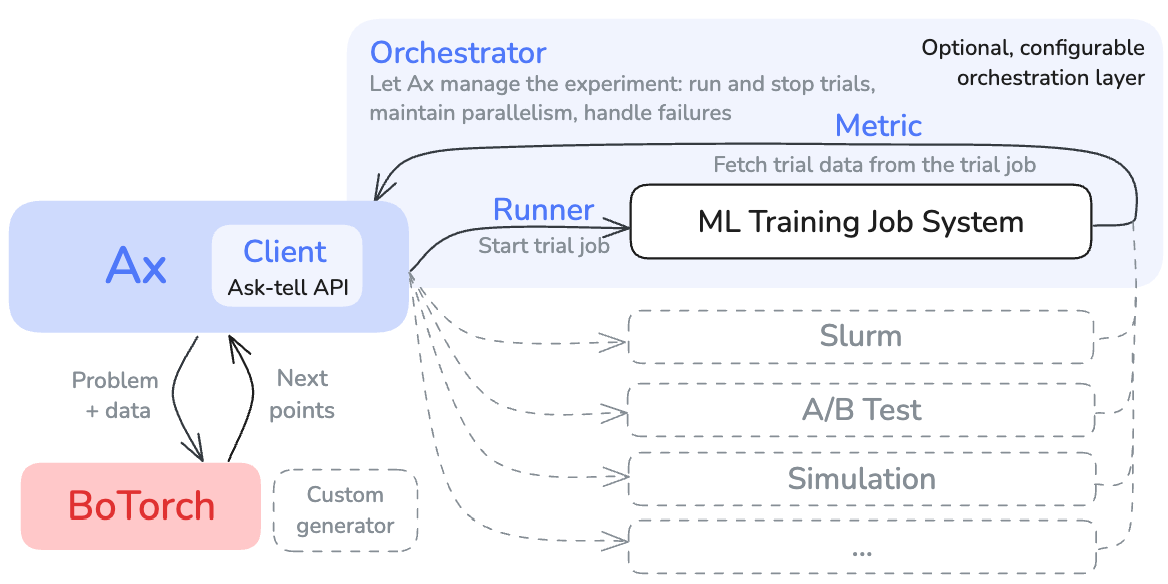
Runner-s and Metric-s typically exchange information about trial deployment
via "run metadata" dictionary (e.g. {"job_id": 12345}), captured on Ax
Trial-s at the time of their deployment by a Runner. Subsequently, a
Metric accesses the metadata to find how to retrieve the data for a given
trial.
Orchestration in the API
Orchestration is available via the Client API (see
Automating Optimization tutorial). The Runner and Metric
implementations are provided by the users. In the Ax API, this is done by
implementing the IRunner and IMetric interfaces, each requiring only one or
two methods. Adding it to a previously "ask-tell" experiment with steps 1-4,
adds steps 5-7 below:
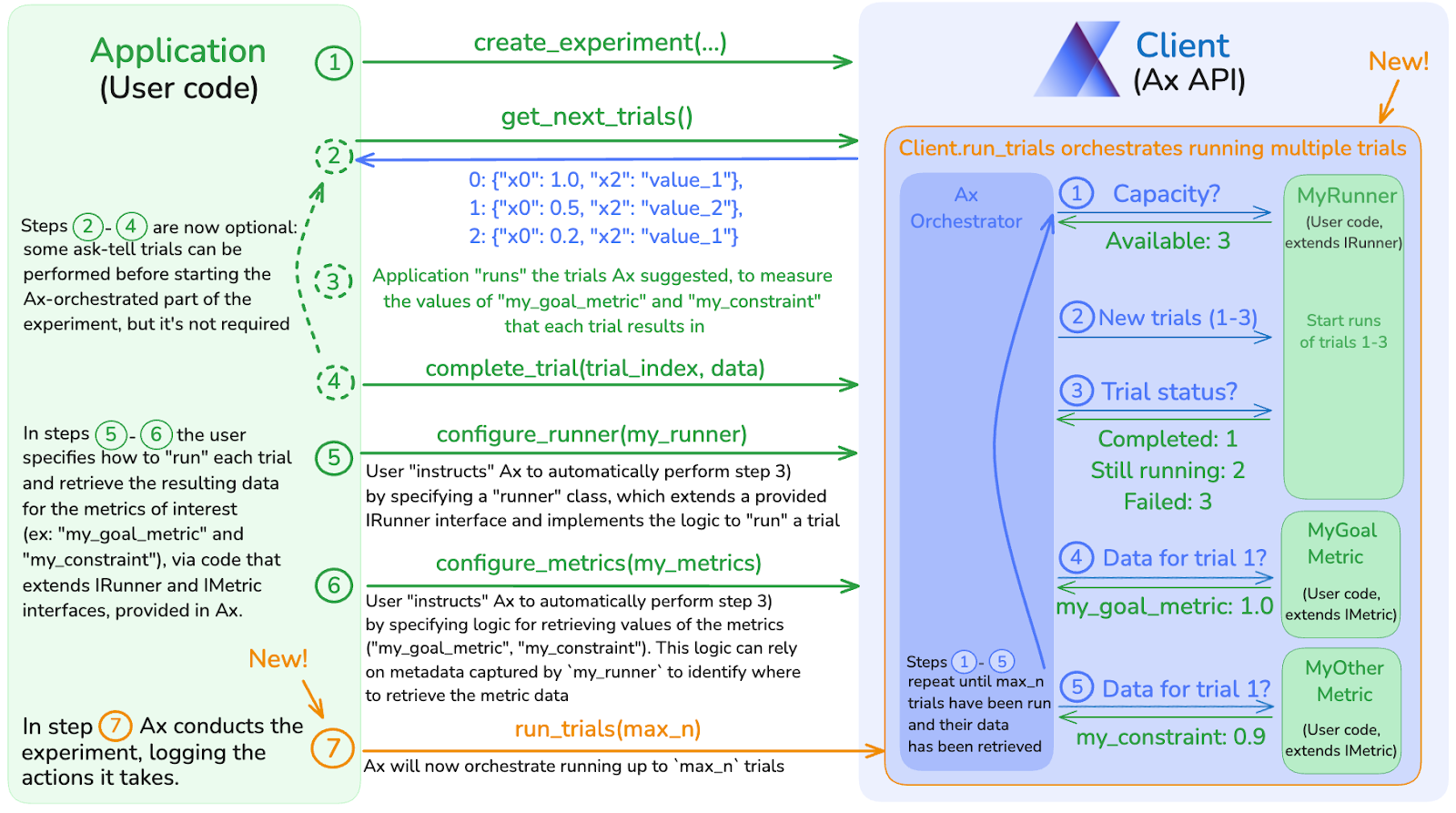
More trials can always be run an ask-tell fashion after the Ax-orchestrated ones
run via Client.run_trials.
Appendix: What makes experiment orchestration get complex?
It might seem that building a robust system for grid search could support a wider range of optimization algorithms without significant changes to orchestration, but in practice a scalable AI-guided optimization and experimentation tool must be informed by the requirements of the cutting-edge optimization methods. Some of the ways in which orchestration of automated optimization loops must be informed by algorithmic considerations are:
- Designing a flexible data model to adapt to new techniques efficiently, without significant changes (e.g. early-stopping, multi-fidelity, multi-objective, preference-based optimization, transfer-learning)
- Guiding users towards an optimal experiment setup (intuitions about "simplifying the problem" often lead to artificially constrained experiments)
- Tolerating the "right" errors: what is safe to just report vs. which errors should be halting to avoid wasting resources?
- Integrating the (varying) costs of evaluating different stages and/or metrics into the optimization algorithm and decisions on when to evaluate what to "learn more with less".
- Querying the "right" data at the "right" time to maximize signal in very noisy problems (using metrics that are available throughout training, proxy metrics etc.)
- Building in diagnostics to make sure that a given optimization behaves correctly while also allowing for fallbacks when users prefer them
- Squeezing insights out of optimization algorithms (e.g. feature/parameter importances, noise levels) wherever possible